【後編】蓄積した情報の活用に向けて~提案型検索手法を取り入れた図研プリサイトの挑戦~
- インタビュー
- データ整理

前編では、「開発のきっかけ」、「利用者(探し手)側の限界」などについてお聞きしました。後編では、「Knowledge Explorerの開発コンセプト、進化、仕組み、利用シーン」などについてお伺いします。
【インタビュイー】
株式会社図研 事業本部長(株式会社図研プリサイト 元代表取締役)上野泰生氏
株式会社図研プリサイト マーケティング部 倉本将光氏
【インタビュアー】
公益社団法人日本文書情報マネジメント協会 文書情報マネージャ―認定セミナー講師 溝上卓也
(前編からのつづき)
溝上:それでは、「Knowledge Explorer」の開発コンセプトについて教えて下さい。
溝上:「PUSH式」というのが提案型なのですね。
溝上:Knowledge Explorerは、既存システムに後付けで導入できると伺いました。これにより導入しやすくなるのではないでしょうか。
溝上:ところで、Knowledge Explorerはいつから開発されているのですか。
2020年のV3では、集合知を取り込みました。例えば、検索結果が有用であった場合、皆さまがSNSなどで使っている「いいね」を入れてもらいます。多くの利用者が「いいね」を入れた文書は、その集団の総意として有効であるに違いないという考え方です。
倉本氏:単に、参照回数が多いから推奨するだけではなく、人のコメントがあるものから参照したいという声をお客さまから頂き機能を追加しています。「いいね」だけでなく、「いまいち」もあります。「いまいち」の利用例としては、「昔は正しかったが、今は変わった」、「法規制が変わった、でも、保存はしておかねばいけない。」などの場合、コメントで連絡します。
溝上:Knowledge Explorerの仕組みを解説頂けますか。 概要図
倉本氏:一言で言えば、検索対象のファイルサーバーにある全ファイルに、タグを打つイメージです。弊社のAIは、ファイル本文の中から、1番重要なのはこの言葉ではないか、と推定する機能を持っています。ですので、ファイルサーバーのファイル毎に、1番重要なのはこれではないか、2番目はこれではないかと推定し、それを重要語DBに、重要語とファイルを紐づけて、溜め込みます。
溝上:技術伝承をこのKnowledge Explorer だけに頼っていいものなのでしょうか。
溝上:それでは最終パートですが、現在の利用シーン、今後の利用シーンについて教えて頂けますでしょうか。4.Knowledge Explorerの開発コンセプト
上野氏:一つはどうやって玉石混交の中からナレッジを浮かび上がらせた状態にするか。もう一つは、気づかない人に気づかせる、問題だと思っていない人に問題を提示するというのが、コンセプトです。つまり、日常の仕事をする中で、「あなたは、これを見ておかないといけないですよ。」とある種お節介を焼くような仕組みでないといけないのかなと考えています。
仕事をしている人が、自ら情報を引っ張りにいくことはない、とわかっているので、「いつも使っているツール」で、例えば、Word、PowerPoint、ExcelやWEBブラウザーを使う中で、ナレッジを手作業で作ったり、メンテナンスするのではなく、AIを使って「フルオート」で集約して、ドキュメントを書いている人が作業している時に、パラパラと目の前に現れる「PUSH式」を考えました。
すなわち、「利用者が意識しなくても”気づき”を与えたい。」と考えました。「有効な資料に辿り着くための気づきを与えるナレッジシステム」として「いつものツールで」、「PUSH式」、「フルオート」で実現することをKnowledge Explorerのコンセプトとしました。
上野氏:そうです。新たな文書を書いているとシステムが自動的に参考にした方がよい文書を提案するということを目指しました。「気づき」を与えてくれるのです。

5.後付けで導入しやすいKnowledge Explorer
上野氏:文書管理システムまで入れ替えようとすると大変なので、今の仕組みはそのままでいいです。大がかりなシステムを持っていなくても、サーバーにドキュメントを入れているレベルからでも始められます。ファイルサーバーをお使いでしたら、フォルダー構造はそのままで、Microsoft SharePoint や富士ゼロックスArcSuite Engineering をお使いでしたら、それにアタッチすることで、ご利用頂けます。その他に、内製でRDBを使った過去トラブル集や文書の管理をされている場合にも、RDBにアタッチできるようになっています。
溝上:まさに「いつものツールで」を実現されたのですね。まず、使ってみようと思った場合、いくらくらいから始められるのですか。
倉本氏:検索対象50万件で最小のライセンス費用は360万円です。詳細は、図研プリサイト「Knowledge Explorer」のホームページに掲載しております。
溝上:お試し感覚でも始めやすいですね。
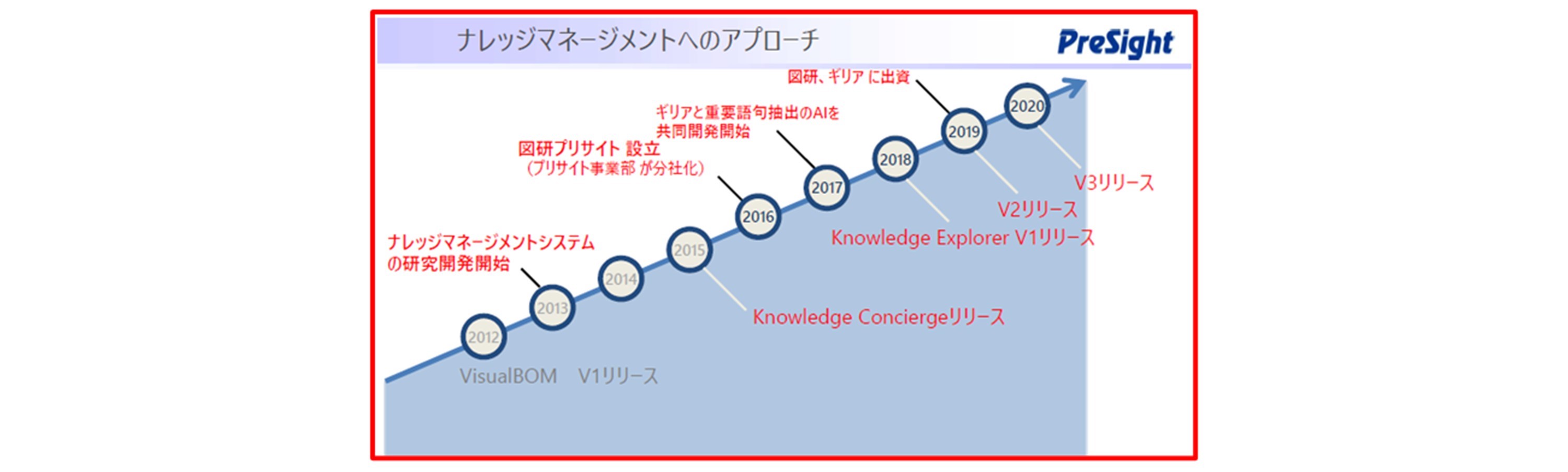
6.Knowledge Explorerの進化
上野氏:Knowledge Explorerの前身であるKnowledge Conciergeを2015年から開発・販売しています。この時の知見の取り出し方は統計処理で行っていました。これだけではなく、実態に合わせた補正をするためにルールベースでの処理も取り入れました。
しかし、開発を進めるうちに、このルールが非常に大きくなってしまい、内部矛盾を引き起こし、メンテナンスが難しい状況になってきました。
そこで、方式を一新してAIを活用しようということになりました。いろいろなAIベンダーさんと話しをしましたが、最終的に深層学習でトップレベルのギリア株式会社に協力頂き、エンジン部分を作り直しました。その際に商品名もリニューアルし、Knowledge Explorerとして、2018年V1をリリースしました。2019年V2では、Office連携のUIを改善しました。
この集合知のポイントの高い文書について、提案の優先順位を上げる仕組みです。また、単に「いいね」だけでなく、何が、どうよかったかをコメントできるようにしており、ハッシュタグも入れられます。いろんな人の意見で良い、悪いを評価していくことによって、ある知見が固められていき、確からしさの確率が上がると言われています。
将来的には、コメントや評価を入れた人のグレード、例えば、シニアだとナレッジの質が高いとAI側で認識して、スコア計算にも用いたいと考えています。
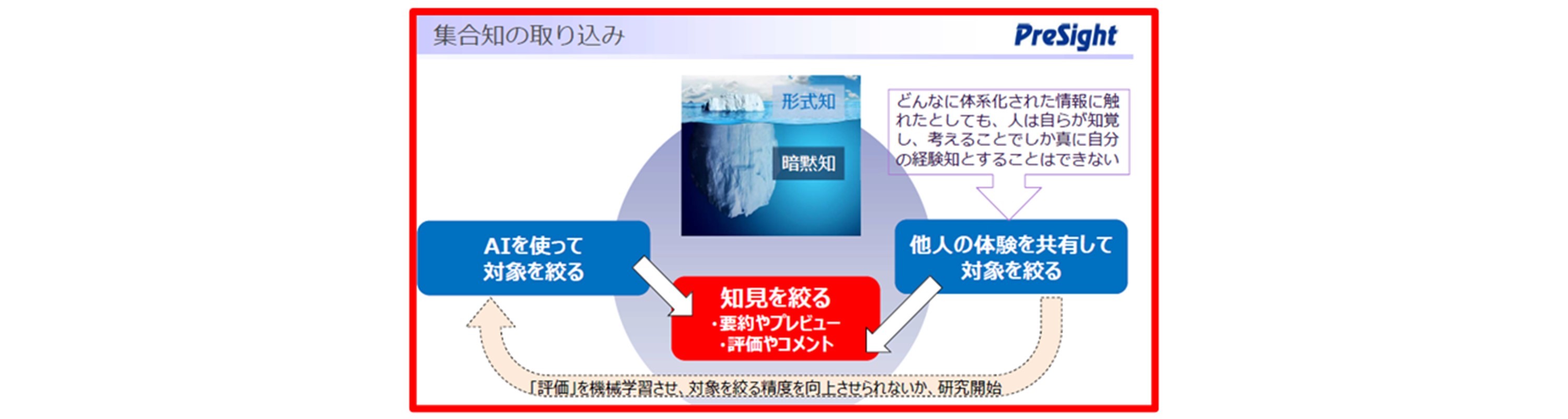
このような情報を全て検索対象から外すのではなく、背景を知らない人が見ても、古い情報を鵜呑みにしないような仕組みとして活用いただけるように機能を組み込んでいます。日常の業務をしながら、使える情報を選別していくという方法を取ることができます。
7.Knowledge Explorerの仕組みの概要
上野氏:まずは、以下の概要図を見て頂けますか。我々はAIを提供しますが、これは学習済のAIです。多くのAIはお客様先で、AIに「覚え込ませよう」から入りますが、我々は学習済のものを提供しますので、ターンキーです。スイッチを入れれば、その時から使えます。
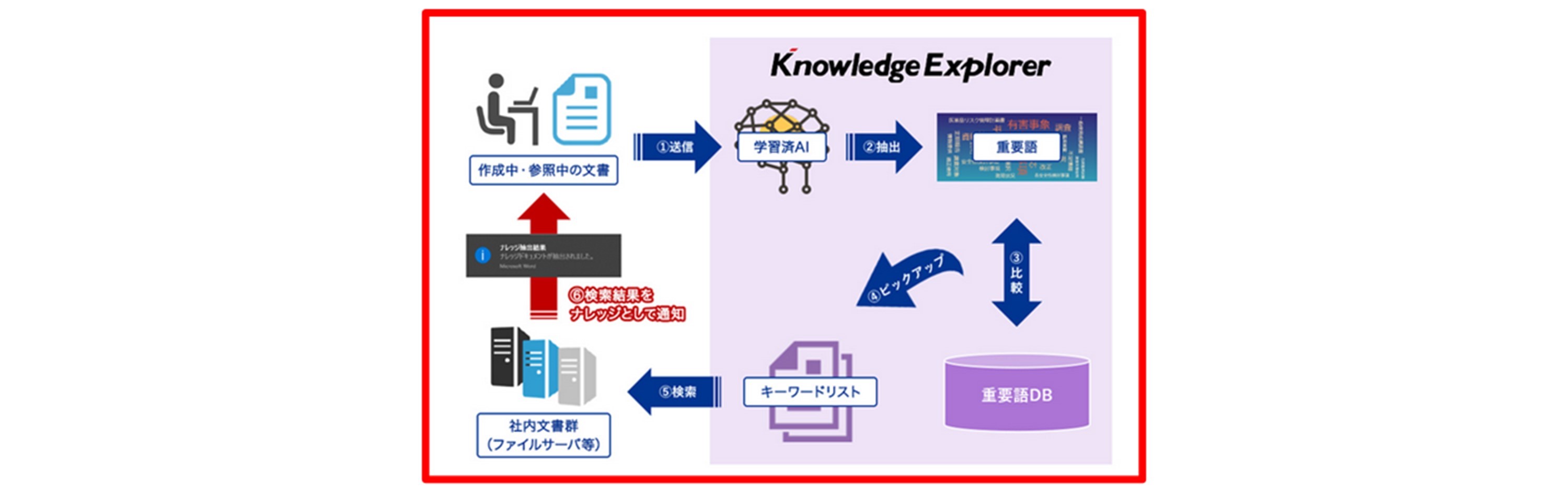
利用者が文書を作成していると、
①その文書の内容をKnowledge Explorerに取り込み
②学習済のAIで、文書中から重要語句を抽出して
③これまで溜め込んでいた重要語DBと比較して
④一致する重要なキーワードを抜き出してリスト化し
⑤この重要キーワードで、社内文書に対し検索を行い、その結果を利用者に通知します。
このように利用者自身は検索のためのキーワードを入力せずに、Knowledge Exploreが自動的に作成中文書からキーワードを見つけ、必要なファイル(文書)を提案します。
8.Knowledge Explorerだけで、技術伝承できるのか
上野氏:それはできないですね。そもそも技術伝承というのはどこまでを指すかにもよりますが。
こういうツールを使うことによって、社内に埋没しているナレッジを社員の皆さまが普通に使うようになってきて、じゃあどういうものを形式知と整備して残さねばいけないか、と認識するきっかけにはなると思いますが、このツールは「暗黙知」を「形式知」に、オートコンバージョンするAIではありません。あくまでも、情報の海の中から、このツールが見つけてきたものをどのように取り扱うか、という人間の判断が入ります。ただ、形式知化の候補の生データとして残しておいて、後に対象とするナレッジを絞り込むという使い方はあると思います。このようなツールを使うことで、どういうドキュメントが検索されているか、読まれているかはログに残りますので、そうすると伝承すべき情報がある程度、かたどられるのではないでしょうか。情報の海にいきなり飛び込んで、ナレッジを整理するのはむぼうであり、やはり事前のトリアージが必要だと思います。
溝上:私などは形式知化したドキュメントを残していく立場だったのですが、形式知化しても利用されないとモチベ―ションが湧かないというところがあるのですが、このツールを使えば、より有益に使われるということがわかります。
上野氏:おっしゃられている通りです。どのドキュメントが読まれているのか、どのドキュメントが「いいね」を付けられているのかは、ログに残っています。それを公表するかは、企業によりますが、自分の書いたドキュメントが多く読まれていれば、書き手もモチベーションが上がりますし、貢献するために、もっといいものを残してやろうと思うかもしれないですね。ボランティアに支えられたWikipediaが良い例だと思います。
どんなに厳密に詳細に、属性付け、タグ付けをしていったとしても、時間が経つと知りたい観点も変わります。形式知化を前面に押し出すのは、理想ではあっても経験上無理だと私は思います。それよりも暗黙知のままでいいので、とにかくみんなで使えるようにして、その結果、本当に必要な普遍的な形式知は何なのか、を見定めていくことが、現実的なやり方ではないかと考えています。
9.利用シーン
倉本氏:我々は図研グループということで、初期ターゲットを製造業のお客さまとしておりました。そのような関係で、「開発資料」、「研究報告書」から知見を掘りだせないか、「不具合対応の過去トラブル履歴」から再発を防止できないか、という観点で利用しているお客さまが増えてきています。
研究開発部門のお客さまでは、社内に保有している論文、特許などを検索対象とし、有益かどうか即座に判断していくことにも使われています。同じ重要ワードが、多く含まれるものを抽出するという機能をエンハンスしましたが、品質保証部門のお客さまでは、この機能を「類似のトラブルを早く見つけ、初動を早め顧客への影響を少なくする」ためにも使われています。
弊社HPに事例を掲載しておりますが、株式会社本田技術研究所、タカノ株式会社、大鵬薬品工業株式会社などのお客さまに利用して頂いております。
溝上:今、新型コロナウイルスの対策で、テレワークが進み、オフィスが分断されますので、このようなツールを使って頂ければと思います。このようなツールを使えば、製造業以外の会社でも競争力が高まると思うのですが、いかがですか。
倉本氏:実は、テレワークの関係だと思いますが、オンラインセミナーへの参加が急増しており、前回は100名を越えました。その中で、非製造業の経営企画部門の方からも相談を受けております。
溝上:本日は、インタビューにご対応頂きましてありがとうございました。

